The Complete Guide to Data Ingestion Architecture for Businesses
Learn how to design and implement effective data ingestion architectures to power your data-driven initiatives.
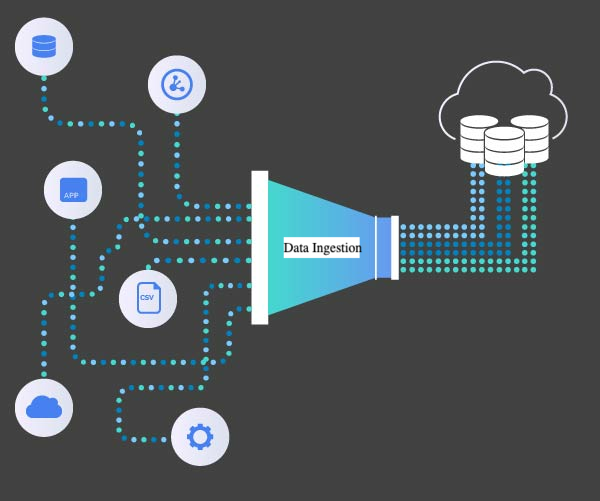
Understanding Data Ingestion
Data ingestion is the process of obtaining and importing data for immediate use or storage in a database. It's the first critical step in the data pipeline that enables organizations to harness the power of their data for analytics, machine learning, and business intelligence.
In today's data-driven business environment, effective data ingestion is more important than ever. Organizations are collecting data from an increasing number of sources—from traditional databases and applications to IoT devices, social media, and third-party APIs. The ability to efficiently ingest this data, in various formats and volumes, is fundamental to deriving value from it.
Key Components of Data Ingestion Architecture
1. Data Sources
Data sources are the origins of the data you want to ingest. These can include:
- Relational databases (MySQL, PostgreSQL, Oracle, SQL Server)
- NoSQL databases (MongoDB, Cassandra, Couchbase)
- APIs and web services
- File systems (local, network, cloud storage)
- Streaming sources (Kafka, Kinesis, IoT devices)
- SaaS applications (Salesforce, HubSpot, Zendesk)
- Legacy systems and mainframes
2. Data Collection Layer
The data collection layer is responsible for extracting data from the sources. This can involve:
- Connectors and adapters for different source systems
- API clients for web services
- Change data capture (CDC) mechanisms for detecting changes in source data
- Agents or collectors deployed close to the data sources
- Web scrapers for collecting data from websites
3. Data Transportation Layer
The transportation layer moves data from sources to the target systems. This includes:
- Messaging systems (Kafka, RabbitMQ, ActiveMQ)
- Data streaming platforms (Kinesis, Pub/Sub)
- ETL/ELT tools and pipelines
- File transfer protocols (FTP, SFTP, HTTP)
- Bulk data movement tools
4. Data Processing Layer
The processing layer transforms and prepares data during ingestion. This may include:
- Data validation and quality checks
- Format conversion (JSON to Parquet, CSV to Avro, etc.)
- Schema validation and enforcement
- Data enrichment and augmentation
- Filtering and aggregation
- Deduplication and error handling
5. Data Storage Layer
The storage layer is where ingested data is stored for further processing or analysis:
- Data lakes (S3, Azure Data Lake, Google Cloud Storage)
- Data warehouses (Snowflake, Redshift, BigQuery)
- Operational databases
- Time-series databases for IoT data
- Specialized storage for specific data types (e.g., image, video)
6. Orchestration and Monitoring
These components manage and monitor the ingestion process:
- Workflow orchestration tools (Airflow, Prefect, Dagster)
- Monitoring and alerting systems
- Logging and auditing mechanisms
- Error handling and recovery processes
- Performance optimization tools
Data Ingestion Patterns and Approaches
Common Data Ingestion Patterns
Batch Ingestion
Processes data in discrete chunks or batches at scheduled intervals. Suitable for large volumes of data where real-time processing is not required.
Use cases: Daily sales reports, monthly financial reconciliation, periodic data warehouse updates
Real-time/Stream Ingestion
Processes data continuously as it's generated. Essential for use cases requiring immediate insights or actions based on incoming data.
Use cases: Fraud detection, real-time monitoring, live dashboards, recommendation engines
Micro-batch Ingestion
A hybrid approach that processes small batches of data at frequent intervals, balancing the efficiency of batch processing with the timeliness of streaming.
Use cases: Near-real-time analytics, operational dashboards, IoT data processing
Change Data Capture (CDC)
Identifies and captures changes made to data sources (inserts, updates, deletes) and replicates only the changes to the target systems.
Use cases: Database replication, data warehouse synchronization, audit trails
Designing an Effective Data Ingestion Architecture
1. Assess Your Requirements
Before designing your data ingestion architecture, carefully assess your requirements:
- Data volume: How much data will you be ingesting?
- Data velocity: How frequently is the data generated and how quickly must it be processed?
- Data variety: What types and formats of data will you be handling?
- Latency requirements: Do you need real-time or near-real-time processing?
- Reliability needs: What are your requirements for data completeness and accuracy?
- Scalability: How will your data volumes grow over time?
2. Choose the Right Ingestion Pattern
Based on your requirements, select the appropriate ingestion pattern or a combination of patterns:
- Use batch ingestion for large volumes of historical data or when real-time processing is not required
- Implement stream ingestion for real-time use cases
- Consider micro-batch for a balance between efficiency and timeliness
- Apply CDC for efficient synchronization of database changes
3. Select Technologies and Tools
Choose technologies that align with your requirements and existing infrastructure:
Data Collection and Transportation
- Apache Kafka: Distributed streaming platform
- Apache NiFi: Data flow automation tool
- AWS Kinesis: Real-time streaming data service
- Google Pub/Sub: Messaging and ingestion for event-driven systems
- Airbyte: Open-source data integration platform
Data Processing
- Apache Spark: Unified analytics engine
- Apache Flink: Stream processing framework
- AWS Glue: Serverless data integration service
- Databricks: Unified data analytics platform
- dbt: Data transformation tool
4. Design for Scalability and Reliability
Ensure your architecture can handle growing data volumes and maintain reliability:
- Implement horizontal scalability to handle increasing data volumes
- Design for fault tolerance with redundancy and failover mechanisms
- Include error handling and dead-letter queues for failed ingestion attempts
- Consider data partitioning strategies for large datasets
- Implement backpressure handling for stream processing
5. Incorporate Data Governance and Security
Build governance and security into your ingestion architecture:
- Implement data lineage tracking to maintain visibility into data origins and transformations
- Apply data quality checks during ingestion
- Ensure compliance with relevant regulations (GDPR, CCPA, HIPAA, etc.)
- Implement encryption for data in transit and at rest
- Apply appropriate access controls and authentication mechanisms
6. Plan for Monitoring and Maintenance
Develop a strategy for ongoing monitoring and maintenance:
- Implement comprehensive logging and monitoring
- Set up alerts for ingestion failures or performance issues
- Establish KPIs for ingestion processes (latency, throughput, error rates)
- Create dashboards for visualizing ingestion metrics
- Develop procedures for troubleshooting and resolving issues
Common Data Ingestion Challenges and Solutions
Challenge 1: Handling Diverse Data Formats
Solution: Implement a flexible schema management approach, use format-agnostic storage like data lakes for raw data, and employ schema-on-read techniques. Consider tools that support multiple data formats natively.
Challenge 2: Ensuring Data Quality
Solution: Implement data validation at ingestion time, use data quality frameworks, establish clear data quality metrics, and create automated processes for handling data quality issues.
Challenge 3: Managing High-Volume Data
Solution: Implement data partitioning, use distributed processing frameworks, consider data sampling for initial analysis, and optimize storage formats (Parquet, ORC, Avro).
Challenge 4: Dealing with Late or Out-of-Order Data
Solution: Use windowing techniques in stream processing, implement watermarking to handle late data, design for idempotent processing, and maintain mechanisms to reprocess data if needed.
Challenge 5: Maintaining Performance as Data Grows
Solution: Design for horizontal scalability from the start, implement auto-scaling capabilities, regularly review and optimize ingestion processes, and consider data lifecycle management to archive or delete older data.
Case Studies: Successful Data Ingestion Architectures
E-commerce Company: Real-time Customer Analytics
An e-commerce company implemented a hybrid ingestion architecture combining CDC for database changes with stream processing for clickstream data. This allowed them to create real-time customer profiles and personalized recommendations, resulting in a 15% increase in conversion rates.
Financial Services: Regulatory Reporting
A financial institution designed a batch ingestion architecture with strong data governance controls for regulatory reporting. By implementing comprehensive data quality checks and lineage tracking during ingestion, they reduced compliance reporting errors by 90% and cut report preparation time by 60%.
Manufacturing: IoT Sensor Data
A manufacturing company implemented a stream processing architecture for ingesting data from thousands of IoT sensors. Using edge processing to filter and aggregate data before transmission, they reduced bandwidth requirements by 70% while enabling real-time monitoring and predictive maintenance.
Future Trends in Data Ingestion
1. Serverless Data Ingestion
Serverless architectures are gaining popularity for data ingestion, offering automatic scaling, reduced operational overhead, and pay-per-use pricing models. This approach is particularly beneficial for variable or unpredictable ingestion workloads.
2. AI-Powered Ingestion
AI and machine learning are being integrated into data ingestion processes to automate schema detection, data quality checks, and anomaly detection. These technologies can also help optimize ingestion performance and resource allocation.
3. Data Mesh Architectures
The data mesh approach treats data as a product and distributes data ownership to domain teams. This paradigm shift affects data ingestion by promoting decentralized ingestion patterns while maintaining centralized governance and discovery.
4. Real-time Everything
As businesses increasingly require real-time insights, data ingestion architectures are evolving to support lower latency and higher throughput. Stream processing is becoming the default rather than the exception for many use cases.
Conclusion
An effective data ingestion architecture is the foundation of any successful data strategy. By understanding the key components, patterns, and best practices outlined in this guide, you can design and implement a data ingestion architecture that meets your current needs while providing the flexibility to adapt to future requirements.
Remember that there is no one-size-fits-all solution for data ingestion. The right architecture for your organization will depend on your specific requirements, existing infrastructure, and business objectives. Take the time to thoroughly assess your needs, select appropriate technologies, and design for scalability, reliability, and governance.
As data continues to grow in volume, variety, and importance, investing in a robust data ingestion architecture will pay dividends in the form of more timely insights, better decision-making, and increased competitive advantage.
Share this article
Subscribe to our newsletter
Get the latest insights on data engineering and analytics delivered to your inbox.